修修补补加上自己的思考完善,终于成功用lxml和Beautiful Soup成功爬取数据并保存啦!
lxml应用案例
爬取糗事百科段子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70import requests
#from retrying import retry
from lxml import etree
import csv
class Qiubai_spider():
def __init__(self):
self.url = "http://www.qiushibaike.com/8hr/page/{}/"
self.headers = {
"User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"
}
#@retry(stop_max_attempt_number=5) #调用retry,当assert出错时候,重复请求5次
def parse_url(self,url):
response = requests.get(url,timeout=10,headers=self.headers) #请求url
#assert response.status_code==200 #当响应码不是200时候,做断言报错处理
print(url)
return etree.HTML(response.text) #返回etree之后的html
def parse_content(self,html):
dataList = []
item_temp = html.xpath('//div[@class="recommend-article"]/ul/li')
#print(len(item_temp))
for item in item_temp:
#获取用户头像地址
avatar = item.xpath("./div/div/a/img/@src")[0]
#为头像地址添加前缀
if avatar is not None and not avatar.startswith("http:"):
avatar = "http:"+avatar
name = item.xpath("./div/div/a/span/text()")[0] #获取用户名
content = item.xpath("./div/a/text()")[0] #获取内容
star_number = item.xpath("./div/div/div/span[1]/text()")[0] #获取点赞数
#comment_number = item.xpath("./div[@class='stats']/span[2]/a/i/text()")[0] #获取评论数
data = {
'avatar':avatar,
'name':name,
'content':content,
'star_number':star_number
#'comment_number':comment_number
}
dataList.append(data)
return dataList
#print("*"*100)
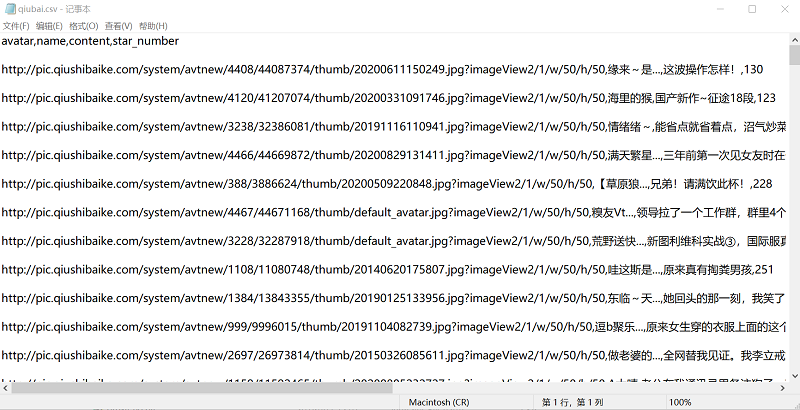
def save_data(self, dataList):
filename = ['avatar', 'name', 'content', 'star_number']
with open('D:……qiubai.csv', 'w', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames = filename)
writer.writeheader()
for i in dataList:
#print(i)
writer.writerow(i)
def run(self):
'''函数的主要逻辑实现
'''
urls = [self.url.format(str(i)) for i in range(1, 14)] #获取到urls
all_data = []
for url in urls:
html = self.parse_url(url) #请求url
dataList = self.parse_content(html) #解析页面内容并把内容存入内容队列
all_data +=(dataList)
self.save_data(all_data)
if __name__ == "__main__":
qiubai = Qiubai_spider()
qiubai.run()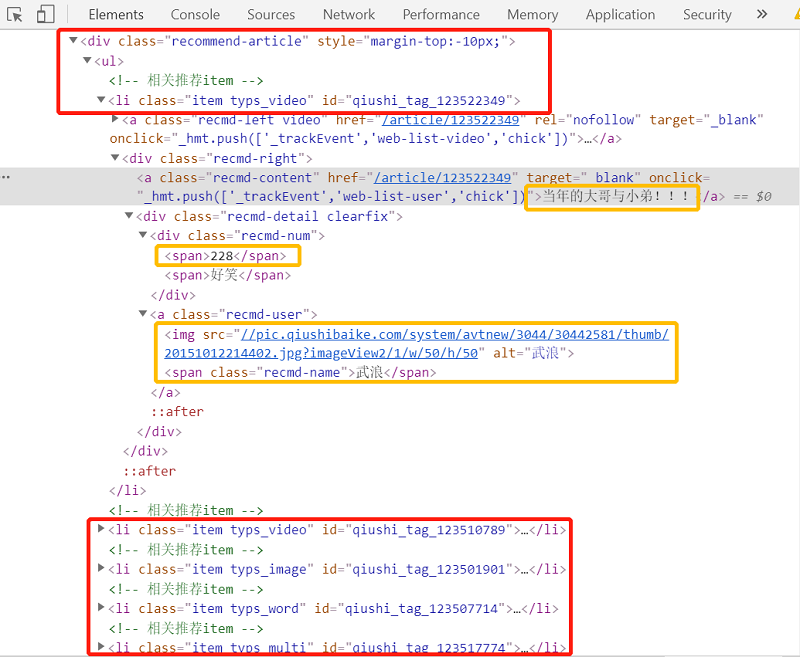
Beautiful Soup应用案例
爬取豆瓣读书1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70import requests
from bs4 import BeautifulSoup
import csv
class doubanBook():
def __init__(self):
self.url = "https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start="
self.headers = {
"User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"
}
def url_create(self, start_page, end_page):
urlList = []
for page in range(start_page, end_page+1):
url = self.url + str(20*(page-1))
urlList.append(url)
return urlList
def parse_url(self, url):
response = requests.get(url,timeout=10,headers=self.headers)
print(url)
return BeautifulSoup(response.content)
def parse_content(self, soup):
bookList = []
results = soup.find_all(class_="subject-item")
for item in results:
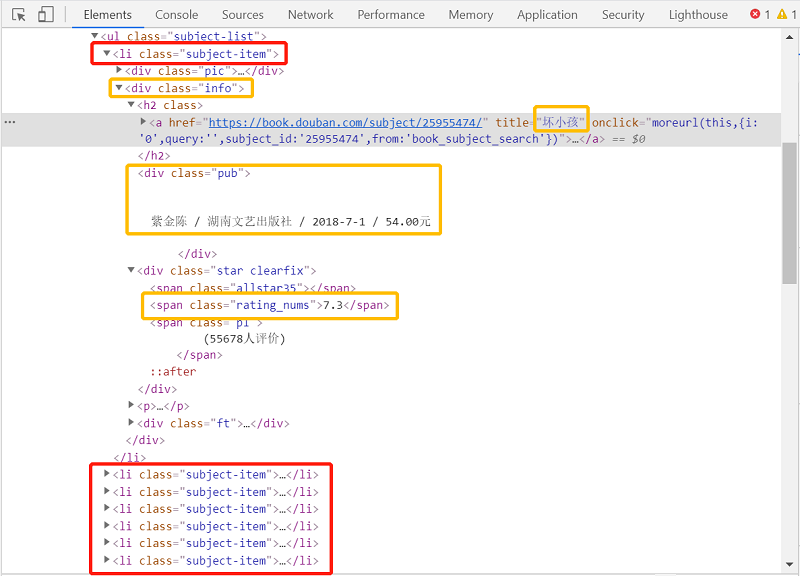
name = item.find(class_="info").find(name="a").get_text().split()[0]
author = item.find(class_="info").find(class_="pub").get_text().split(' / ')[0].replace('\n','').replace(' ','')
price = item.find(class_="info").find(class_="pub").get_text().split(' / ')[-1].replace('\n', '').replace(' ','')
scoreObj = item.find(class_="star clearfix").find(class_="rating_nums")
score = scoreObj.get_text().split()[0] if len(scoreObj) > 0 else None
if score is not None:
score = score
else:
score = "无评分"
book = {
'书名':name,
'作者':author,
'价格':price,
'评分':score
}
bookList.append(book)
return bookList
def save_data(self, bookList):
filename = ['书名', '作者', '价格', '评分']
with open('D:……doubanBook.csv', 'w', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames = filename)
writer.writeheader()
for i in bookList:
#print(i)
writer.writerow(i)
def run(self):
'''函数的主要逻辑实现
'''
start_page = int(input("爬取开始页面:"))
end_page = int(input("爬取结束页面:"))
urlList = self.url_create(start_page, end_page)
all_data = []
for url in urlList:
soup = self.parse_url(url) #请求url
bookList = self.parse_content(soup) #解析页面内容并把内容存入内容队列
all_data +=(bookList)
self.save_data(all_data)
if __name__ == "__main__":
doubanBook().run()