
1 一些好用的R包
1.1 plyr包
plyr包提供了一整套工具集来处理列表、数组和数据框,把复杂的数据分割成几个部分,用某个函数分别对各个部分进行处理,最后把这些结果综合到一起。主要函数是ddply()函数:ddply(data, .(var1, var2), fun, ...)
需要用到的统计汇总函数:subset()对数据取子集transform()进行数据变换,计算分组统计量(如各组的标准差),并且加到原数据上去。colwise()用来向量化一个普通函数,即能把原本只接受向量输入的函数变成可以接受数据框输入的函数,它返回的是一个新的函数。相应的,numcolwise()只对数值类型的列操作,catcolwise()只对分类类型的列操作。
1 | > library(plyr) |
1.2 dplyr包
filter()筛选行,逻辑运算有一个简写x %in% y,用于选取出x 是y 中的一个值时的所有行。arrange()排列行,使用desc()可以按列进行降序排列。select()选择列,可以使用starts_with()、contains()、everything()等辅助函数。mutate()添加新变量,如果只想保留新变量,可以使用transmute()函数。summarize()进行分组摘要,经常和group_by()函数联合起来使用,其可以改变函数的作用范围,使得从在整个数据集上操作变为在每个分组上分别操作。
管道操作:%>%,可以读作“然后”。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71> library(dplyr)
> library(nycflights13)
> filter(flights, month == 11 | month == 12)
# A tibble: 55,403 x 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 11 1 5 2359 6 352 345
2 2013 11 1 35 2250 105 123 2356
3 2013 11 1 455 500 -5 641 651
4 2013 11 1 539 545 -6 856 827
5 2013 11 1 542 545 -3 831 855
6 2013 11 1 549 600 -11 912 923
7 2013 11 1 550 600 -10 705 659
8 2013 11 1 554 600 -6 659 701
9 2013 11 1 554 600 -6 826 827
10 2013 11 1 554 600 -6 749 751
# ... with 55,393 more rows, and 11 more variables: arr_delay <dbl>,
# carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
# air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>
#上面语句还可以表示为:
> nov_dec <- filter(flights, month %in% c(11, 12))
#根据arr_delay列队数据集进行降序排列
> arrange(flights, desc(arr_delay))
#选择flights数据集中的year, month和day列
> select(flights, year, month, day)
#和everything()使用,将几个变量移到数据框开头
> select(flights, time_hour, air_time, everything())
#添加新变量
> mutate(flights,
+ gain = arr_delay - dep_delay,
+ speed = distance / air_time * 60
+ )
#summarize()进行分组摘要
> by_day <- group_by(flights, year, month, day)
> summarize(by_day, delay = mean(dep_delay, na.rm = TRUE))
# A tibble: 365 x 4
# Groups: year, month [12]
year month day delay
<int> <int> <int> <dbl>
1 2013 1 1 11.5
2 2013 1 2 13.9
3 2013 1 3 11.0
4 2013 1 4 8.95
5 2013 1 5 5.73
6 2013 1 6 7.15
7 2013 1 7 5.42
8 2013 1 8 2.55
9 2013 1 9 2.28
10 2013 1 10 2.84
# ... with 355 more rows
#管道操作
> (delays <- flights %>%
+ group_by(dest) %>%
+ summarize(count = n(),
+ dist = mean(distance, na.rm = TRUE),
+ delay = mean(arr_delay, na.rm = TRUE)) %>%
+ filter(count > 20, dest != 'HNL'))
# A tibble: 96 x 4
dest count dist delay
<chr> <int> <dbl> <dbl>
1 ABQ 254 1826 4.38
2 ACK 265 199 4.85
3 ALB 439 143 14.4
4 ATL 17215 757. 11.3
5 AUS 2439 1514. 6.02
6 AVL 275 584. 8.00
7 BDL 443 116 7.05
8 BGR 375 378 8.03
9 BHM 297 866. 16.9
10 BNA 6333 758. 11.8
# ... with 86 more rows
常用的摘要函数
分散程度度量:sd(x)、IQR(x)、mad(x)
秩的度量:min(x)、quantile(x, 0.25)、max(x)
排秩:min_rank(x)将最小值排在最前面,使用min_rank(desc(x))可以让最大值排在最前面
定位度量:first(x)、nth(x, 2)、last(x)
计数:n()不需要任何参数,返回当前分组的大小;sum(!is.na(x))计算非缺失值的数量;n_distinct(x)计算出唯一值的数量;count(x, wt = y)可以选择加权变量y对x进行计数。
逻辑值的计数和比例:sum(x > 10)和mean(y == 0)
2 向量化操作
sapply()可以输入向量、数据框和列表,对其以输入的函数进行向量化计算;lapply()也和sapply()函数一样,区别在于返回结果的形式是一个列表。如果想将该结果转换为一个整齐的矩阵,有三种方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29> myfunc <- function(x) {
+ ret <- c(mean(x), sd(x))
+ return(ret)
+ }
> mylist <- as.list(iris[, 1:4])
> result <- lapply(mylist, myfunc)
> result
$Sepal.Length
[1] 5.8433333 0.8280661
$Sepal.Width
[1] 3.0573333 0.4358663
$Petal.Length
[1] 3.758000 1.765298
$Petal.Width
[1] 1.1993333 0.7622377
> t(as.data.frame(result))
[,1] [,2]
Sepal.Length 5.843333 0.8280661
Sepal.Width 3.057333 0.4358663
Petal.Length 3.758000 1.7652982
Petal.Width 1.199333 0.7622377
#还可以:
> t(sapply(result, '['))
#或者:
> do.call('rbind', result)apply()和sapply()函数一样,只是其中多了一个参数MARGIN,其值为1,表示以行为计算单位,其值为2,表示以列为计算单位。tapply()按变量的取值进行划分。第一个参数是计算的对象,第二个参数是划分数据的依据,第三个参数是计算所用的函数。aggregate()和tapply()函数类似,不过前者的功能略强于后者,而且以数据框形式输出。
1 | > set.seed(1) |
mapply()用于两个参数同时需要变化的情况,如计算九九乘法表,是sapply()的增强版,可以处理3个及以上参数的向量化计算问题。outer():如果只处理两个参数,outer()也比较方便。replicate()能让某个函数重复调用多遍,在统计模拟中非常有用。
1 | > vec1 <- vec2 <- 1:9 |
3 数据转换整理
3.1 长宽格式互转
宽型数据:各变量取值类型一致,而变量以不同列的形式构成,又称为非堆叠数据。
长型数据:各变量取值在一列,而对应的变量名在另一列。又称为堆叠数据,只要在一列中存在分类变量,都可以将其看做是长型数据。
两种数据可以通过stack()和unstack()进行互相转换,然后计算分析结果。
如果想一步直接得到分析结果,可以使用更为强大的reshape2包:dcast()作用是将长型数据进行汇总计算,思路与aggregate()和plyr包的ddply()函数很相似。这些函数使用的前提是,数据中已经存在分类变量,根据分类变量划分数据,再计算某个数值变量。其中,aggregate是最弱的,只能按单个变量划分数据,计算单个数值对象;dcast要强一些,可以按多个变量划分数据,但也只能计算单个数值对象;ddply是最强的数据整理函数,它可以按多个变量划分数据,并计算整个数据框的所有变量,在自定义函数的配合下极为灵活。melt()作用是将一个宽型数据融合成一个长型数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44> subdata <- iris[, 4:5]
> data_w <- unstack(subdata)
> head(data_w)
setosa versicolor virginica
1 0.2 1.4 2.5
2 0.2 1.5 1.9
3 0.2 1.5 2.1
4 0.2 1.3 1.8
5 0.2 1.5 2.2
6 0.4 1.3 2.1
> colMeans(data_w)
setosa versicolor virginica
0.246 1.326 2.026
> library(reshape2)
> dcast(subdata, Species~., value.var = 'Petal.Width', fun = mean)
Species .
1 setosa 0.246
2 versicolor 1.326
3 virginica 2.026
#用ddply()函数实现
> myfuns <- function(x){
+ mean(x$Sepal.Length)
+ }
> ddply(iris, 'Species', myfuns)
Species V1
1 setosa 5.006
2 versicolor 5.936
3 virginica 6.588
> iris_long <- melt(iris, id = 'Species')
> head(iris_long)
Species variable value
1 setosa Sepal.Length 5.1
2 setosa Sepal.Length 4.9
3 setosa Sepal.Length 4.7
4 setosa Sepal.Length 4.6
5 setosa Sepal.Length 5.0
6 setosa Sepal.Length 5.4
> dcast(iris_long, formula = Species~variable, value.var = 'value', fun = mean)
Species Sepal.Length Sepal.Width Petal.Length Petal.Width
1 setosa 5.006 3.428 1.462 0.246
2 versicolor 5.936 2.770 4.260 1.326
3 virginica 6.588 2.974 5.552 2.026
3.2 数据的拆分与合并
3.2.1 拆分
常规的数据分拆其实就是取子集,使用subset()函数即可完成。非常规一点的数据拆分是按照某个分类变量进行,可以用split()和unsplit()完成。1
2
3
4> iris_splited <- split(iris, f = iris$Species)
> class(iris_splited)
[1] "list"
> iris_all <- unsplit(iris_splited, f = iris$Species)
3.2.2 合并连接
merge()函数:1
2
3
4
5
6> datax <- data.frame(id = c(1, 2, 3), age = c(23, 34, 41))
> datay <- data.frame(id = c(1, 2, 4), name = c('Tom', 'John', 'Ken'))
> merge(datax, datay, by = 'id')
id age name
1 1 23 Tom
2 2 34 John
键的概念:用于连接每对数据表的变量,是能唯一标识观测的变量(或变量集合)。有两种类型:
主键:唯一标识其所在数据表中的观测。
外键:唯一标识另一个数据表中的观测。
根据dplyr包中的函数,连接也可以分为:
内连接:inner_join(),保留同时存在于两个表中的观测,容易丢失观测
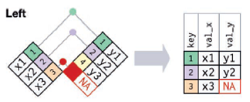
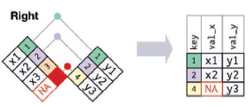
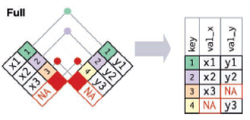
外连接:保留至少存在于一个表中的观测,有三种类型:
-左连接:left_join(),保留x中的所有观测,最常用
-右连接:right_join()保留y中的所有观测
-全连接:full_join()保留x和y中的所有观测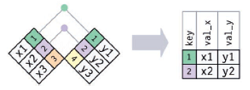
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20> inner_join(datax, datay, by = 'id')
id age name
1 1 23 Tom
2 2 34 John
> left_join(datax, datay, by = 'id')
id age name
1 1 23 Tom
2 2 34 John
3 3 41 <NA>
> right_join(datax, datay, by = 'id')
id age name
1 1 23 Tom
2 2 34 John
3 4 NA Ken
> full_join(datax, datay, by = 'id')
id age name
1 1 23 Tom
2 2 34 John
3 3 41 <NA>
4 4 NA Ken
merge()、dplyr连接操作与SQL三者之间的联系:
- 本笔记参考书目:Hadley Wickham的《ggplot2:数据分析与图形艺术》、Hadley Wickham &
Garrett Grolemund的《R数据科学》以及李舰&肖凯的《数据科学中的r语言》
