
Rattle是R中一个用于数据挖掘的图形交互界面(GUI),可快捷处理常见的数据挖掘问题,从数据的整理到模型的评价,Rattle给出了完整的解决方案。
1 Rattle的安装
首先需要先下载并安装GTK+和GGobi:1
2
3
4
5
6
7
8
9
10#GTK+地址
https://sourceforge.net/projects/gladewin32/files/gtk%2B-win32-runtime/2.12.9/
#GGobi
http://www.ggobi.org/downloads/
> install.packages("rattle", dependencies=TRUE)
> install.packages("rattle",repos="http://rattle.togaware.com")
> install.packages("RGtk2")
> library(rattle)
> rattle()
按道理说这样应该就可以了,但是bug该来还是会来,比如出现:Failed to load RGtk2 dynamic library, attempting to install it.
这说明gtk没有安装成功,于是我把RGtk2卸掉(在Rstudio中的packages面板中点击RGtk2 包右边的叉行按钮,把它删掉),然后关掉Rstudio重启,重新安装一遍RGtk2 就可以了!
这里不得不说一下我的曲折经过:刚开始我是看到有些博客安利了一个“rattle修复工具”,好不容易注册了结果处处都要钱,真是疯了。幸好我没买,因为成为会员真的很贵……然后发现另外一位网友的经验:手动去下载RGtk2 包,再在Rstudio界面的packages面板中点击install,安装方式选择本地压缩包,进行重新安装。不过还是没有成功,原因还是上面那个。这时我发现library下并没有这个包,想着我还是让Rstudio自己装吧,这次不行说明我和Rattle没有缘分,结果居然成功了!
Rattle初始界面:
2 Rattle功能简介
Data:选择数据源,输入数据。Explore:执行数据探索,理解数据分布情况。Test:提供各种统计检验。Transform:可以变换数据的形式。Cluster:数据聚类,包括k-均值聚类、系统聚类和双聚类(biclustering)。Associate:关联规则方法。Model:包含多种算法——决策树、随机森林、组合算法、支持向量机、线性模型、人工神经网络、生存分析。Evaluate:模型评估,包括混淆矩阵(Error Matrix)、模型风险图(Risk)、ROC曲线、得分表等。Log:数据挖掘过程的记录,可以给出所进行Rattle操作的代码。
3 数据探索
在Data下可以导入CSV文件、ARFF数据、ODBC数据(包含市面上所有数据库)、R Dataset数据、SPSS数据集等等。这里导入Rattle包自带的weather.csv数据集:

Explore主要用于数据探索,包括数据总体情况(Summary)、分布情况(Distribution)、相关系数矩阵(Correlation)、主成分分析(Principal Components)以及各变量之间的交互作用(Interactive)。
3.1 描述性统计
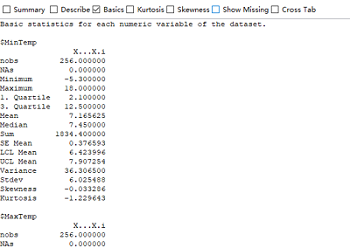
Summary获取描述统计量,对数值型变量提供最小值、第一四分位数、中位数、均值、第三四分位数和最大值,对因子型或逻辑型变量提供频数统计。如左下图。Basic对数值型变量提供更详细的描述性统计,包括:记录数、缺失值个数、最小值、最大值、第一四分位数、第三四分位数、均值、中位数、求和、均值标准误、均值95%置信区间的上下限、方差、偏度和峰度。如右下图。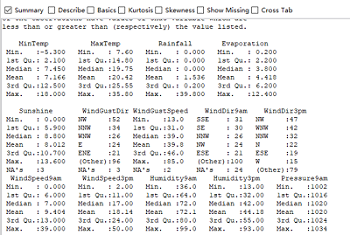
3.2 数据分布
Distribution选项以可视化的方式,给出各个变量的分布特征,可以勾选相应的图形选项,按执行按钮绘图。对数值型变量,可以画箱线图、直方图、累计分布图和benford图;对于类别变量,可以画条形图、点图和马赛克图。
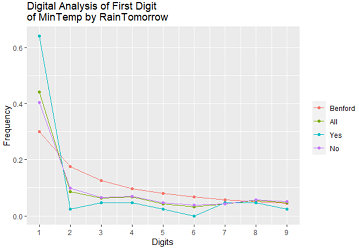
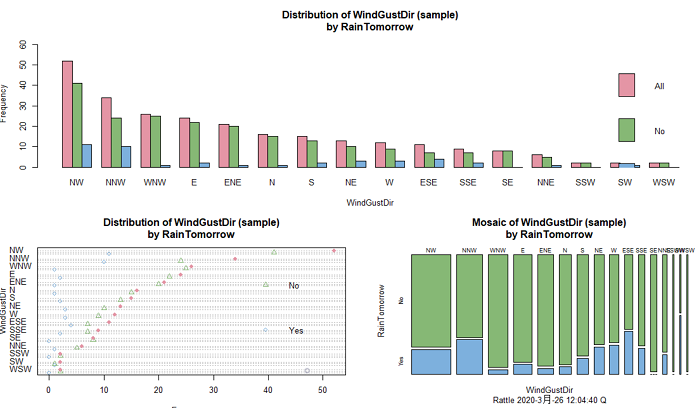
3.3 相关性
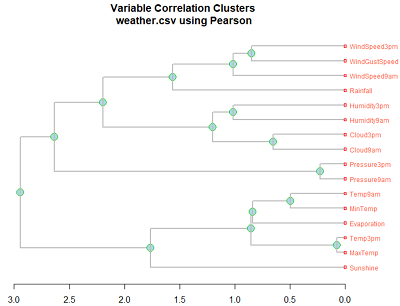
Correlation选项计算数值变量间的相关系数,并对结果进行可视化展示(右下图),其中红色表现负相关,蓝色为正相关,颜色越浅相关系数(绝对值)越小。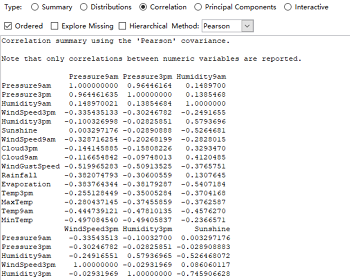
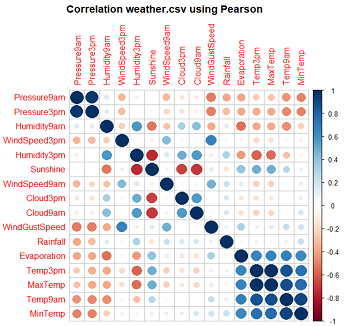
Hierarchical计算层次相关性,输出一个可视化结果,其使用变量间的相关性按层次聚类法(系统聚类法)来对变量进行分类,聚类的距离是变量间的相关性。
3.4 主成分分析
Principal Components进行主成分分析。主成分分析作为一种数据降维的方法,在数据探索中可以发现数据集中用来解释样本方差的重要变量。样本的各个主成分就是用来描述数据最大方差的互不相关的原始变量的线性组合。Rattle计算主成分有两种方法:一是计算样本协方差矩阵的特征值和特征向量(Eigen),结果给出标准差、贡献率和累计贡献率;另一种是对数据矩阵进行奇异值分解(SVD),结果给出标准差、主成分系数、贡献率和累计贡献率。两种结果都给出碎石图和biplot图。
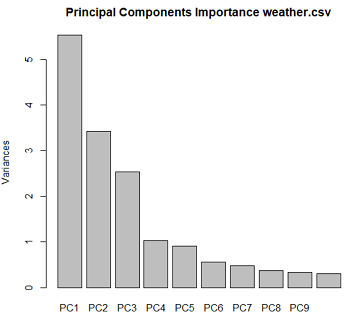
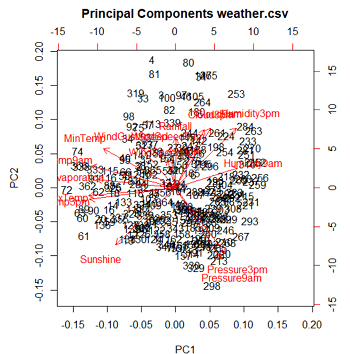
左上图为SVD法进行主成分分析给出的碎石图,可以看出,第一主成分的贡献率较大,其他的贡献率则较小。右上图为biplot图,这个图给出了样本点在第一主成分和第二主成分坐标系下的位置(即主成分得分),同时表示了这些样本点在原始变量坐标系中的相对位置,图中红色箭头即表示原始变量坐标系。原始变量以红色标出,黑色为样本点。
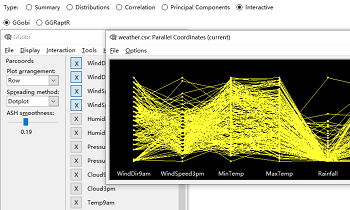
3.5 交互图
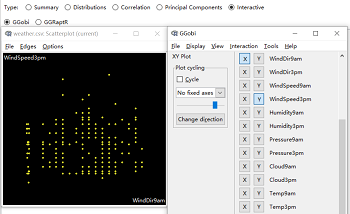
GGobi有许多吸引眼球的优点,包括交互式散点图、柱状图、平行坐标图、时间序列图、散点图矩阵和三维旋转的综合使用。左下图为散点图,可以选Cycle,查看不同变量间的散点图分布情况;Display选项可以选择不同的图表类型,如平行图(右下图)、散点图矩阵等。利用交互选项的GGRaptR可以调出GGRaptR网页式界面。
4 模型构建
4.1 聚类分析
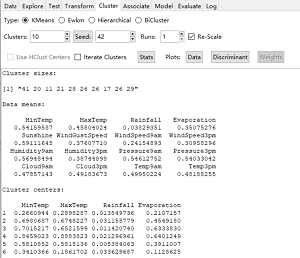
Cluster模块下有常用的聚类分析:K-Means聚类和层次聚类(Hierarchical Cluster)。
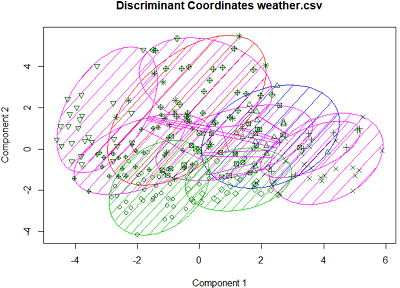
对weather数据集建立K-Means聚类模型,结果输出各类别所包含的样本数(Cluster sizes)、训练集各变量的均值(Data means)、各类别均值(Cluster centers)和各类别的组内平方和(左下图)。执行画图(Plots)的Data按钮,会打印前五个数值变量的散点图矩阵,Discriminant按钮会生成样本投影图,并用数字标明每个样本所属类别(右下图)。
4.2 关联规则
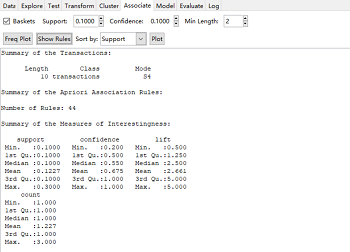
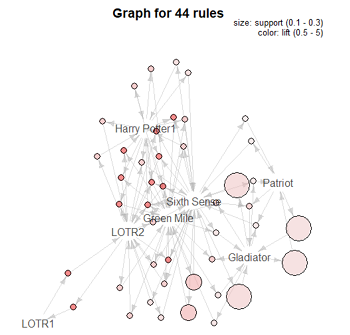
Associate模块可以实现关联规则著名的Apriori算法。默认最小支持度阈值(min-sup)是0.100,最小置信度阈值(min-conf)是0.100,每个项集所含项数的最小值是2,可以根据实际情况进行参数调整设置。导入rattle包自带的dvdtrans.csv数据集,参数按照默认设置,对该数据集建立关联规则结果,一共生成44条规则,同时给出了支持度、置信度和提升度的最小值、第一四分位数、中位数、均值、第三四分位数和最大值等重要信息(左下图)。Show Rules按钮输出生成的关联规则,可以通过Sort by下拉框选择置信度或提升度等排序方式(右下图)。
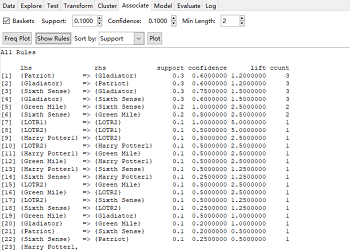
单击Freq Plot按钮可以生成商品的交易频率图;单击Plot按钮可以对关联规则进行可视化: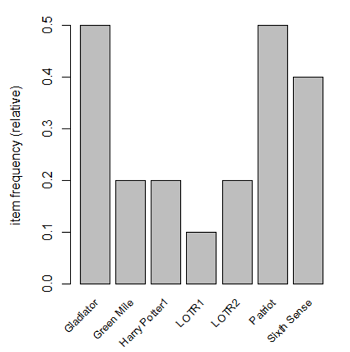
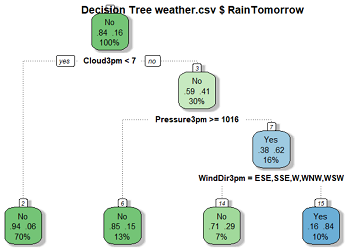
4.3 决策树和随机森林
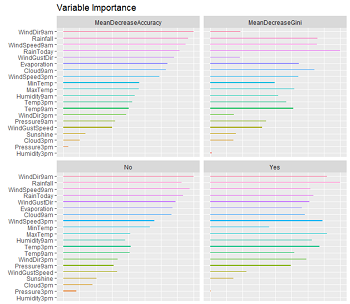
Model模块下可以实现决策树和随机森林建模。利用weather数据集进行建模,选择Tree,单击Draw按钮可以生成决策树图(左下图)。选择Forest实现随机森林建模,单击Importance按钮对各变量重要性进行可视化(右下图)。
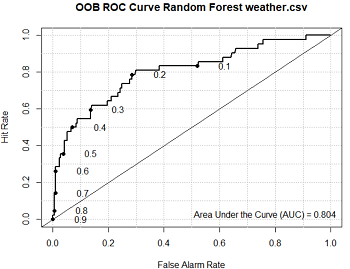
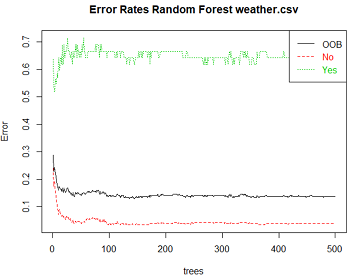
OOB ROC生成OOB ROC曲线;Errors可以生成每棵树的OOB,因变量为Yes或No时的误差率。
5 模型评估
5.1 混淆矩阵和风险图
利用rattle包中的审计数据集audit中的70%数据生成决策树模型,并对test数据集建立混淆矩阵(左下图)。
模型风险图通常也叫累计增益图,该图主要提供了二分类模型评估中的另一种透视图,可以通过Evaluate模块下的Risk选项直接生成。右下图为审计数据集建立决策树的风险图。

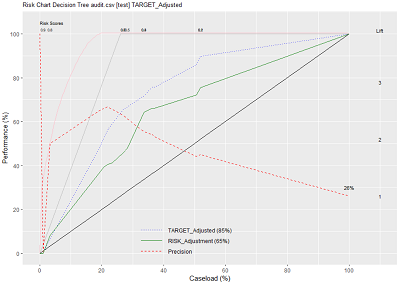
在理解风险图时,首先需要找到该问题的核心,井且找到该模型的特定环境。在本案例中,这个特定的情节就是对纳税人所进行的审计活动。假设每年将会对100000 人进行审计,根据风险图中所示,那么就将会存在26000 人需要对他们各自的纳税申报表进行调整。这个比率(26%) 称之为strike rate。
假设现有的资金量仅允许针对50000 名纳税者进行审计工作,这50%的样本是不是同样有26%的纳税人(即13000人)需要进行调整呢?非也,图中基准线(对角线)上方的实线(即绿色实线)所代表的就是根据模型对数据进行重新排列后,新得到的模型还能具有原模型多少性能的百分比。此时,对于50000个审计对象,将可能有16900(26000的65%)需要进行调整(RISK_Adjustment为65%)。
基准线上方的紫色虚线(TARGET_Adjusted)是根据模型中的风险变量而绘制的,其提供的是对于模型中风险大小的一个衡量标准。本案例中的风险变量是模型自带变量RISK_Adjustment和前面进行纳税申报表调整所产生的金额。
在比较不同模型的风险图时,通常寻找图形下方面积较大的模型,即靠近图像左上角的图形所代表的模型性能通常优于靠近基准线的模型(其实也就是比较TARGET_Adjusted的大小)。
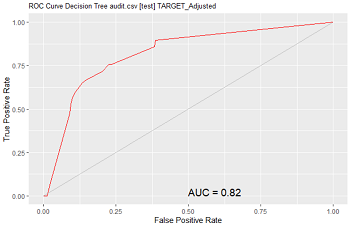
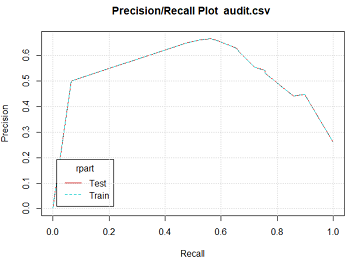
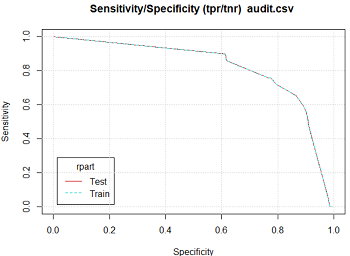
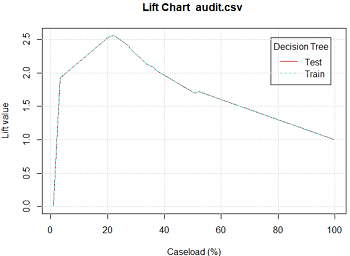
5.2 ROC图及相关图表
ROC图像的形式与风险图较为类似,不同之处在于各自的坐标轴不同。与ROC相类似的还有精确度与敏感度图Precision、敏感度与特异性图Sensitivity、增益图Lift。
几个概念:
误判率:根据模型预测结果同真实值之间的差别而计算得出,误判率 = 误判的样本个数 / 样本总数。与之相关的还有正确 / 错误的肯定判断、正确 / 错误的否定判断。
精确度:指正确的肯定判断与全部肯定判断的比值,主要用于评价模型针对肯定的预测结果的准确度。
敏感度:指正确的肯定判断与真实的肯定结果的比率,主要用于评价模型具体能够鉴别出实际样本的肯定结果中有多少肯定结果。
特异性:用于评价模型具体能够鉴别出实际样本的否定结果中有多少个否定结果,该值刚好与模型的敏感度测评范围相异。
这4种图两两之间的区别在于各自坐标轴所代表的的内容不同:
ROC图:横纵坐标轴分别是错误肯定判断率与正确肯定判断率
精确度与敏感度图:横轴为敏感度,纵轴为精确度
敏感度与特异性图:横轴为特异性,纵轴为敏感度
增益图:横轴代表抽取原始样本的比例
下面依次是ROC图、精确度与敏感度图、敏感度与特异性图、增益图:
- 本笔记基于黄文和王正林编著的《数据挖掘:R语言实战》整理
