
朴素贝叶斯模型属于有监督的学习算法,是专门解决分类问题的模型。该分类器的实现思想是通过已知类别的训练数据集,计算样本的先验概率,然后利用贝叶斯概率公式测算未知样本属于某个类别的后验概率,最终以最大后验概率所对应的类别作为样本的预测值。该算法应用广泛,常见的领域如垃圾邮箱识别、电子设备中的手体字识别、广告技术中的推荐系统、医疗健康中的病情诊断、互联网金融中的欺诈识别等。
优点:
-算法在运算过程中简单而高效;
-拥有古典概率的理论支撑,分类效率稳定;
-对缺失数据和异常数据不太敏感。
缺点:
-模型的判断结果依赖于先验概率,分类结果存在一定的错误率;
-对输入的自变量X要求具有相同的特征(如均为数值型或离散型);
-模型的前提假设在实际应用中很难满足等。
通常会根据自变量X不同的数据类型选择不同的贝叶斯分类器,如高斯贝叶斯分类器、多项式贝叶斯分类器和伯努利贝叶斯分类器。
1 高斯贝叶斯分类器
当数据集中的自变量X均为连续的数值型,则使用高斯贝叶斯分类器,其关键的核心是假设数值型变量服从正态分布,如果实际数据近似服从正态分布,分类结果会更加准确。使用sklearn子模块naive_bayes中的GaussianNB类实现该分类器的计算功能。
首先导入常用的程序库和读取数据集:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn import naive_bayes
skin = pd.read_excel(r'C:\Users\Q\Desktop\Skin_Segment.xlsx')
#设置正例和负例
skin.y = skin.y.map({2:0, 1:1})
skin.y.value_counts()
**out:**
0 194198
1 50859
Name: y, dtype: int64
该数据集的自变量为不同人群图片的三原色B、G、R,因变量为二分变量,值为1和2,表示样本在对应的B、G、R值下是否为人类面部皮肤,在处理中将2设置为0,即负例,表示非人类面部皮肤,将1设置为1,表示正例,说明样本为人类面部皮肤。
接下来拆分数据集用于模型的构建和评估:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(skin.iloc[:, :3], skin.y,
test_size = 0.25,
random_state = 1234)
gnb = naive_bayes.GaussianNB()
gnb.fit(X_train, y_train)
gnb_pred = gnb.predict(X_test)
#各类别的预测数量
pd.Series(gnb_pred).value_counts()
**out:**
0 50630
1 10635
dtype: int64
结果显示了预测为负例和正例的样本个数。为检验模型在测试数据集上的预测效果,需要构建混淆矩阵和绘制ROC曲线:1
2
3
4
5
6
7from sklearn import metrics
#绘制混淆矩阵
cm = pd.crosstab(gnb_pred, y_test)
sns.heatmap(cm, annot = True, cmap = 'GnBu', fmt = 'd')
plt.xlabel('Real')
plt.ylabel('Predict')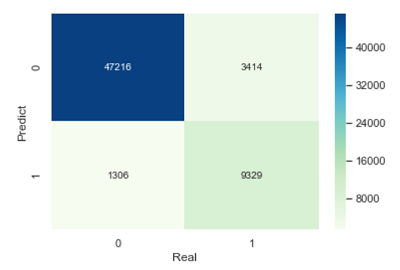
1
2
3
4
5
6
7
8
9
10
11
12
13
14print('模型的准确率为:', metrics.accuracy_score(y_test, gnb_pred))
print('模型的评估报告:\n', metrics.classification_report(y_test, gnb_pred))
**out:**
模型的准确率为: 0.9229576430261976
模型的评估报告:
precision recall f1-score support
0 0.93 0.97 0.95 48522
1 0.88 0.73 0.80 12743
micro avg 0.92 0.92 0.92 61265
macro avg 0.90 0.85 0.88 61265
weighted avg 0.92 0.92 0.92 61265
混淆矩阵和评估报告的解释可见上几节内容。通过准确率、精准率和覆盖率的对比,模型的预测效果还是非常理想的。
接下来绘制ROC曲线:1
2
3
4
5
6
7
8
9
10y_score = gnb.predict_proba(X_test)[:, 1]
fpr, tpr, threshold = metrics.roc_curve(y_test, y_score)
roc_auc = metrics.auc(fpr, tpr)
plt.stackplot(fpr, tpr, color = 'steelblue', alpha = 0.5, edgecolor = 'black')
plt.plot(fpr, tpr, color = 'black', lw = 1)
plt.plot([0, 1], [0, 1], color = 'red', linestyle = '--')
plt.text(0.5, 0.3, 'ROC curve (area = %0.2f)' % roc_auc)
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')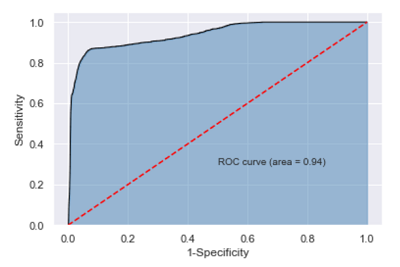
计算得到的AUC值为0.94,超过用于评判模型好坏的阈值0.8,故可以认为构建的贝叶斯分类器是非常理想的。
2 多项式贝叶斯分类器
当数据集中的自变量X均为离散型变量,则应该选用多项式贝叶斯分类器,计算可直接导入sklearn子模块naive_bayes中的MultinomialNB类。
应用是蘑菇数据集,根据自变量蘑菇的形状、表面光滑度、颜色、生长环境等,判断因变量蘑菇是否有毒。首先读取数据:1
2mushrooms = pd.read_csv('C:/Users/Q/Desktop/mushrooms.csv')
mushrooms.head()
表中的所有变量均为字符型的离散值,由于Python建模过程中必须要求自变量为数值类型,因此需要对这些变量做因子化处理,即把字符值转换为对应的数值,可用pandas模块中的factorize函数对离散的自变量进行数值转换:1
2
3
4columns = mushrooms.columns[1:]
for column in columns:
mushrooms[column] = pd.factorize(mushrooms[column])[0]
mushrooms.head()
需要注意的是,factorize函数返回的是两个元素的元组,第一个为转换成的数值,第二个为数值对应的字符水平,所以在类型转换时,需要通过索引方式返回因子化的值。
接下来对数据集进行拆分和建模:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#拆分数据集
Predictors = mushrooms.columns[1:]
X_train, X_test, y_train, y_test = train_test_split(mushrooms[Predictors],
mushrooms['type'],
test_size = 0.25,
random_state = 10)
#构建模型
mnb = naive_bayes.MultinomialNB()
mnb.fit(X_train, y_train)
mnb_pred = mnb.predict(X_test)
#绘制混淆矩阵
cm = pd.crosstab(mnb_pred, y_test)
sns.heatmap(cm, annot = True, cmap = 'GnBu', fmt = 'd')
plt.xlabel('')
plt.ylabel('')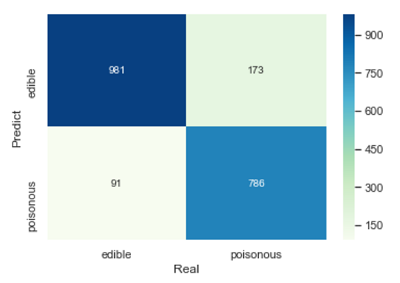
1
2
3
4
5
6
7
8
9
10
11
12
13
14print('模型的准确率为:', metrics.accuracy_score(y_test, mnb_pred))
print('模型的评估报告:\n', metrics.classification_report(y_test, mnb_pred))
**out:**
模型的准确率为: 0.8700147710487445
模型的评估报告:
precision recall f1-score support
edible 0.85 0.92 0.88 1072
poisonous 0.90 0.82 0.86 959
micro avg 0.87 0.87 0.87 2031
macro avg 0.87 0.87 0.87 2031
weighted avg 0.87 0.87 0.87 2031
结果总体上还是比较理想的。
接下来绘制ROC曲线:1
2
3
4
5
6
7
8
9
10
11y_score = mnb.predict_proba(X_test)[:, 1]
fpr, tpr, threshold = metrics.roc_curve(y_test.map({'edible':0, 'poisonous':1}),
y_score)
roc_auc = metrics.auc(fpr, tpr)
plt.stackplot(fpr, tpr, color = 'steelblue', alpha = 0.5, edgecolor = 'black')
plt.plot(fpr, tpr, color = 'black', lw = 1)
plt.plot([0, 1], [0, 1], color = 'red', linestyle = '--')
plt.text(0.5, 0.3, 'ROC curve (area = %0.2f)' % roc_auc)
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')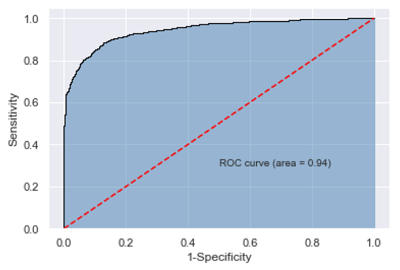
需要注意的是,当因变量为字符型的值时,子模块 metrics的roc_curve必须传入数值型的因变量,因此代码中对字符值和数值做了映射,否则会报错。
由结果来看,AUC值为0.94,模型的效果也是非常不错的。
3 伯努利贝叶斯分类器
当数据集中的自变量X均为0-1二元值时(例如在文本挖掘中,判断某个词语是否出现在句子中,出现用1表示,不出现用0表示),通常会优先选择伯努利贝叶斯分类器,该分类器通过sklearn子模块naive_bayes中的BernoulliNB类实现。
数据是用户对购买的蚊帐进行评论,Type变量为评论对应的情绪,首先导入数据:1
2evaluation = pd.read_excel(r'C:\Users\Q\Desktop\Contents.xlsx',sheetname = 0)
evaluation.head(10)
接下来运用正则表达式,将评论中的数字、英文等文本删除:1
evaluation.Content = evaluation.Content.str.replace('[0-9a-zA-Z]', '')
经过对文本的初步清洗后,下一步对文本进行切词,这里需要引用用户自定义的词库和停止词。利用词典的目的是将无法正常切割的词实现正确切割,使用停止词的目的是将句子中无意义的词语删除(如“的”、“啊”、“我们”等)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#这个包需要自行安装才可以导入
import jieba
#加载自定义词库
jieba.load_userdict(r'C:\Users\Q\Desktop\all_words.txt')
#读入停止词
with open(r'C:\Users\Q\Desktop\mystopwords.txt', encoding = 'UTF-8') as words:
stop_words = [i.strip() for i in words.readlines()]
#构造切词的自定义函数,并在切词过程中删除停止词
def cut_word(sentence):
words = [i for i in jieba.lcut(sentence) if i not in stop_words]
#切完的词用空格隔开
result = ' '.join(words)
return(result)
#调用自定义函数,对评论内容进行批量切词
words = evaluation.Content.apply(cut_word)
words[:5]
**out:**
0 想 卖家 给我发 错货 四个 连接 铁通 块钱 便宜 廉价 退货
1 垃圾 \n 钳子 摄细 装 \n 管子 很软 \n 评价 垃圾
2 我就 无语 难弄 .. 说明书 .. 过段 差评 ..
3 不满意 写 落地 差一截 垂度 ~ 夹子 夹 没有 超市 买 质量好 换季 卖得 价钱 便宜
4 标的 到达 快递 四天 蚊帐 底座 太小 管壁 太薄 蚊帐 也没 宣传 垂地 购物 失败
Name: Content, dtype: object
接下来利用如上的切词结果,构造文档词条矩阵,矩阵的每一行代表一个评论内容,每一列代表切词后的词语,矩阵的元素为词语在文档中出现的频次:1
2
3
4
5
6
7
8
9
10
11
12from sklearn.feature_extraction.text import CountVectorizer
#计算每个词在各评论中的次数,并将稀疏度为99%以上的词删除
counts = CountVectorizer(min_df = 0.01)
#文档词条矩阵
dtm_counts = counts.fit_transform(words).toarray()
#矩阵的列名称
columns = counts.get_feature_names()
#将矩阵转为数据框
X = pd.DataFrame(dtm_counts, columns = columns)
y = evaluation.Type
X.head()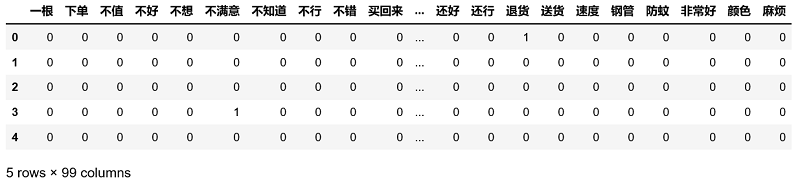
代码中的CountVectorizer(min_df = 0.01)表示词语所对应的文档数目必须在所有文档中至少占1%的比例,最终得到词条矩阵中的99个变量。
有了以上结果,接下来就是对数据进行拆分、建模和评估:1
2
3
4
5
6
7
8
9
10
11
12X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.25,
random_state = 1)
bnb = naive_bayes.BernoulliNB()
bnb.fit(X_train, y_train)
bnb_pred = bnb.predict(X_test)
#构造混淆矩阵
cm = pd.crosstab(bnb_pred, y_test)
sns.heatmap(cm, annot = True, cmap = 'GnBu', fmt = 'd')
plt.xlabel('Real')
plt.ylabel('Predict')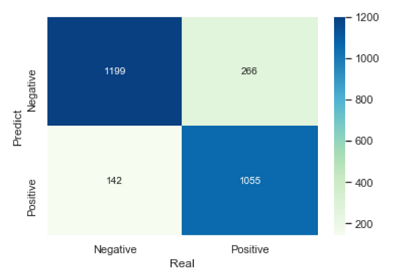
1
2
3
4
5
6
7
8
9
10
11
12
13
14print('模型的准确率为:', metrics.accuracy_score(y_test, bnb_pred))
print('模型的评估报告:\n', metrics.classification_report(y_test, bnb_pred))
**out:**
模型的准确率为: 0.8467317806160781
模型的评估报告:
precision recall f1-score support
Negative 0.82 0.89 0.85 1341
Positive 0.88 0.80 0.84 1321
micro avg 0.85 0.85 0.85 2662
macro avg 0.85 0.85 0.85 2662
weighted avg 0.85 0.85 0.85 2662
从结果来看,模型的预测效果还是不错的。
最后绘制模型在测试数据集上的ROC曲线:1
2
3
4
5
6
7
8
9
10
11y_score = bnb.predict_proba(X_test)[:,1]
fpr,tpr, threshold = metrics.roc_curve(y_test.map({'Negative':0, 'Positive':1}),
y_score)
roc_auc = metrics.auc(fpr, tpr)
plt.stackplot(fpr, tpr, color = 'steelblue', alpha = 0.5, edgecolor = 'black')
plt.plot(fpr, tpr, color = 'black', lw = 1)
plt.plot([0, 1], [0, 1], color = 'red', linestyle = '--')
plt.text(0.5, 0.3, 'ROC curve (area = %0.2f)' % roc_auc)
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')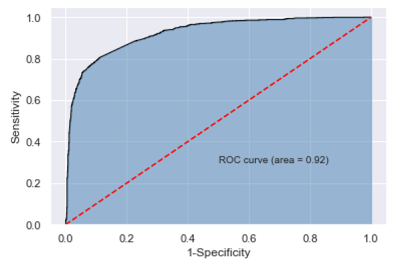
绘制的ROC曲线对应的AUC值为0.92,结合模型准确率、覆盖率等指标,可以认为该模型在测试数据集上的预测效果是非常理想的。
总结
本文的三种朴素贝叶斯分类器,选择主要依赖自变量X的数据类型。
当自变量X均为连续的数值型,则使用高斯贝叶斯分类器;
当自变量X均为离散型变量,则应该选用多项式贝叶斯分类器;
当自变量X均为0-1二元值,则会优先选择伯努利贝叶斯分类器。
朴素贝叶斯分类器的核心假设为自变量之间是条件独立的,该假设的主要目的四为了提高算法的运算效率,如果实际数据集中的自变量不满足独立性假设时,分类器的预测效果往往会产生错误。
- 本笔记基于刘顺祥的《从零开始学Python数据分析与挖掘》整理
